 This week we successfully piloted a new collaborative design methodology, designed to enable rapid design iterations through conversation between educators and text analytics teams. Two of the HETA project team, Andrew Gibson (technical lead) and Simon Buckingham Shum (project lead), worked with two UTS academics who use reflective writing as part of their teaching, Cherie Lucas (Discipline of Pharmacy, Grad. School of Health) and Adrian Kelly (Faculty of Engineering & IT).
This week we successfully piloted a new collaborative design methodology, designed to enable rapid design iterations through conversation between educators and text analytics teams. Two of the HETA project team, Andrew Gibson (technical lead) and Simon Buckingham Shum (project lead), worked with two UTS academics who use reflective writing as part of their teaching, Cherie Lucas (Discipline of Pharmacy, Grad. School of Health) and Adrian Kelly (Faculty of Engineering & IT).
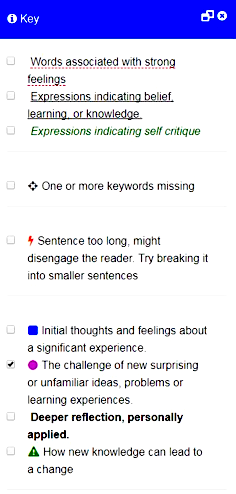
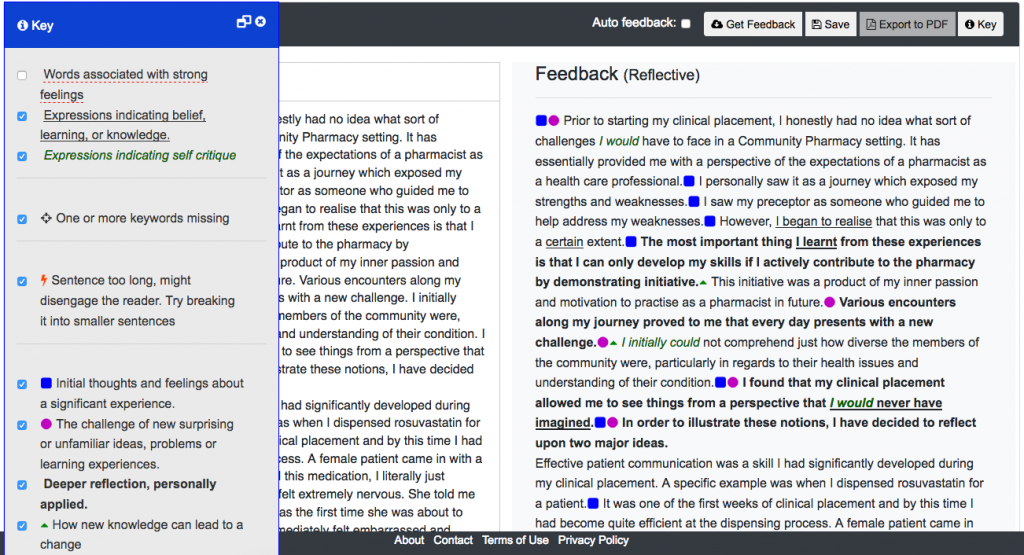
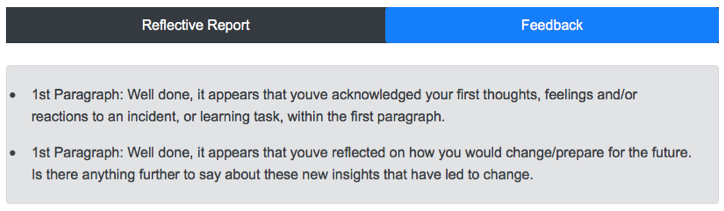
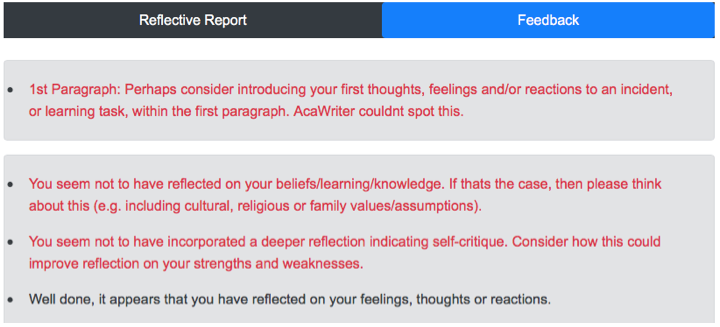
The AcaWriter tool has a parser for the genre of reflective writing, which identifies a range of features that have been established as hallmarks of good writing (see right panel). The goal was to improve the performance of the first category shown, which depends on detection of emotion and affect. This was poorly calibrated in an early version, which meant that it was generating far too many ‘false positives’, that is, highlighting words that were not genuine cases, leading to visual noise and undermining the tool’s trustworthiness. An extract is shown below, where it is clear that many of the red underlined words are spurious:

This is due to the fact that dimensional data in the lexicon was indexed against a model of arousal, valence and dominance (Warriner,Kuperman & Brysbaert, 2013) whose values had not been calibrated for this context. At present this feature has been removed from the user interface, but it needed to be restored in an acceptable form.
The academics brought samples of student writing to use as test cases, and the writing analytics team used a Jupyter notebook (get the code) to rapidly prototype different thresholds for the emotion and affect module in TAP.
We spent a morning working through the examples, examining the words that were identified as we varied the thresholds on different dimensions. The results are now being implemented in AcaWriter, for review by the educators.
The key insights gained from a morning’s work cover both process and product:
The academics could work with the Jupyter notebook output. As a prototyping development tool it is far from pretty for non-technical users:

But with Andrew explaining what they were seeing, the whole group got into a ‘rhythm’ of loading a new document, testing thresholds for arousal, valence and dominance, reviewing the words, and agreeing on what seemed to be the optimum values. Over time, it became clear that only one dimension needed to be manipulated to make useful differences.
Rapid design iterations. As a writing analytics team, we were excited that the process we had envisaged did indeed enable rapid code iterations through focused conversations. This wold have taken many emails or less focused meetings, if the parser was not evolving ‘in the moment’.
Pedagogy and text analytics interwoven. We were also excited to see how conversation between the educators about how AcaWriter was being used, or might be used, might interweave around the coding. For instance, as it became clearer how the parser’s performance might impact the student experience, there was common agreement on the importance of erring on the side of caution, setting the thresholds higher at the acceptable price of increasing the false negatives). It also emerged that there were too many false positives for words not also embedded in sentences that were making one of the three rhetorical moves attended to in the tool (signified by the icons), thus providing a filtering rule that could be codified in the user interface.
The educators valued being involved, and seeing ‘under the hood’. The educators greatly appreciated being involved in this process, feeling that they now understood in much greater depth how the tool worked. They could see that their input was directly shaping the engine powering the vehicle: to pursue the metaphor, having been inducted into the world of the engineers, their understanding now went beyond the normal dashboard offered to drivers, as did their influence over the vehicle’s performance.
The Jupyter notebook evolved to support this process. As the workshop proceeded, we made a range of small changes to the way the notebook displayed its output, to assist the specific task at hand of reviewing the values assigned to words in the text. More ideas were generated which can now be implemented to enhance the experience. For example, it became apparent during the process that it might be helpful if analytics from different texts (Good reflection vs Poor reflection) could be compared.
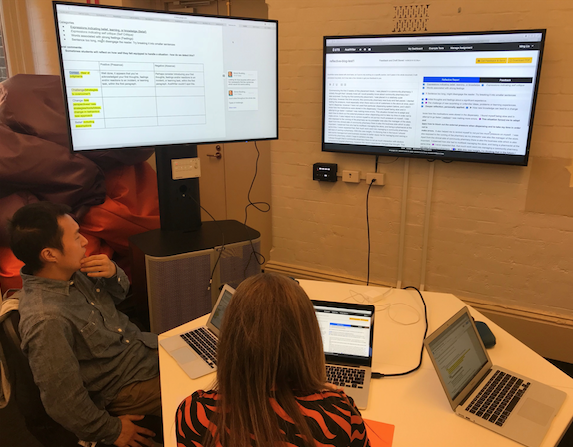
The ergonomics of facilitating participatory design. The physical setup of a space can enhance or obstruct the intended process.

We started out as shown on the left, but could not see or access all the materials, so switched to the second setup. It proved effective to have the notebook up on the wall display as the primary working screen, and AcaWriter on a second display in order to see its output for a sample text. In the future I’d have this on a second, larger display, positioned under the main display to facilitate switching and gesturing.
It really helped to provide paper copies of the texts, plus highlighter pens for the educators to annotate each piece as they familiarised themselves with it, and for comparison with the two machine outputs. These shots show the kind of interaction that this setup afforded.

To conclude, this pilot has provided us with convincing evidence that this methodology worked as a practical way to tune a writing feedback tool in close dialogue with the educators who will use it in their practice. We broke for lunch, and had hoped to implement the changes in AcaWriter in the afternoon, for review by end of the day. We didn’t quite get there on this occasion, but will be reviewing the new version with the academics soon.
No doubt this process can be improved further, so we welcome your comments, and encourage you to adopt/adapt this to your own contexts.
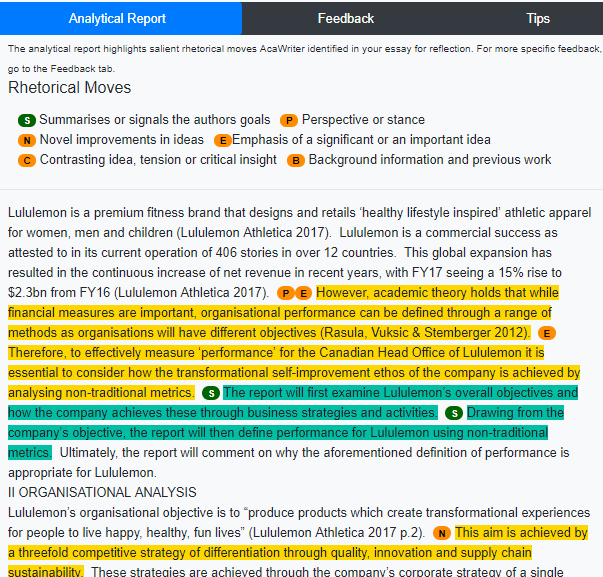
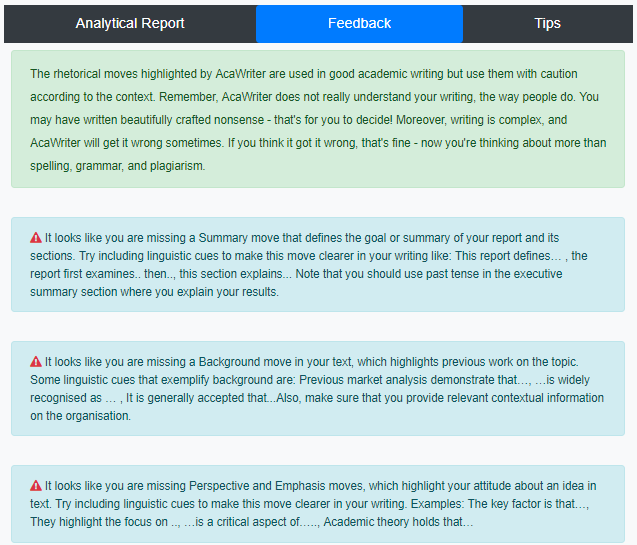

 undertook a pilot of AcaWriter over the 2018 academic year. This preliminary evaluation highlighted the high potential of the tool to provide early feedback on students’ writing. The pilot also revealed certain technical complications that require further improvement to ease broader dissemination and uptake. The outcomes for the small study serve as a useful base to establish a technical roadmap for future development.
undertook a pilot of AcaWriter over the 2018 academic year. This preliminary evaluation highlighted the high potential of the tool to provide early feedback on students’ writing. The pilot also revealed certain technical complications that require further improvement to ease broader dissemination and uptake. The outcomes for the small study serve as a useful base to establish a technical roadmap for future development.



 After some
After some